
Generative AI, and large language models (LLMs) more specifically, have taken the world by storm. And yet, the technology is not new by any means.
The famous paper that started it all was published in 2017. And it took 5 more years of painstaking effort before the technology matured enough to be useful. In 2022, with the release of ChatGPT, LLMs have become the decade’s technology.
Since that fated day, many new companies have entered the generative AI market, launching a worldwide arms race to build the best models. But despite the incredible investments in the field, LLM use cases remain somewhat limited.
One of the potential use cases with the most promise is translation, at least according to these AI labs. But, From our perspective in the language industry, the pattern of new technologies disappointing is all too familiar.
With that in mind, we will investigate Anthropic’s claims and assess Claude’s translation capabilities.
What is Claude 3?
Claude is an AI language model developed by Anthropic. It’s designed to understand and generate human-like text, assist with many tasks, and engage in conversations. Claude 3 is Anthropic’s latest model family. It includes three versions:
- Opus – Most capable model, excels at complex tasks
- Sonnet – Balanced performance and speed for everyday use
- Haiku – Fastest model, optimized for simpler tasks
Anthropic’s latest addition, Claude 3.5 Sonnet, is an evolution of the Claude 3 model family. They consider it an addendum rather than a new model, hence the 3.5 designation.
Why did we pick Claude instead of ChatGPT?
Can you use Claude for translation? Anthropic's take
Anthropic’s paper claims that Claude 3 Opus boasts significantly improved multilingual capabilities compared to its predecessors. The leap is so large that it unlocks translation as a viable use case.
This isn’t my assertion, but Anthropic’s 👇

The key phrase to note is “translation services.” It implies capabilities beyond casual, non-professional translation, thus inviting more rigorous scrutiny. You can see further translation claims here and here.
Despite these claims, I’ve yet to find any test or benchmark directly assessing the model’s translation capabilities. That said, let’s dive into Claude 3’s multilingual capabilities.
The paper first addresses multilingual capabilities in section 5. According to the researchers, Claude was trained and tested on multilingual tasks including:
- Translation
- Summarization
- Multilingual reasoning
But it’s in section 5.6 that we can get access to some specifics. Anthropic mainly used two benchmarks here:
- A multilingual math benchmark (MGSM).
- A multilingual general reasoning benchmark (MMLU).
The problem here is clear. These benchmarks are good enough to assess a model’s ability to communicate in different languages (i.e., to be a good chatbot). But they are not enough to test Claude’s translation capabilities.
In the MGSM benchmark, Claude scored over 90% in eight-plus languages, including French, Russian, Simplified Chinese, Spanish, Bengali, Thai, German, and Japanese. In the multilingual MMLU, Claude scored slightly above 80% in German, Spanish, French, Italian, Dutch, Russian, and several other languages.
Beyond these standardized benchmarks, Anthropic employs human feedback as an evaluation tool. Their approach mirrors the Elo rating system I discussed in the leaderboard section. While admittedly limited, I agree with the authors that it’s a solid framework. It assesses an elusive metric that benchmarks struggle to capture: user perception.
Language, unlike many other fields, is inherently flexible. In our industry, what should matter is how end-users perceive a given written piece, not whether it adheres to an arbitrary benchmark. This user-centric approach aligns more closely with real-world translation applications.
But it’s worth noting that Anthropic’s testing, while comprehensive in scope, lacks depth. This limitation leaves us with an incomplete picture. So, it’s time to turn our attention to academia for a more nuanced answer to our question: Are Claude’s translation skills truly relevant in our industry?
What does the research say?
While there are many, many papers that study LLMs, those focusing on pure translation are limited. Of these papers, the vast majority rely on OpenAI’s models (GPT-3.5, GPT-4, etc.).
When searching through the arXiv library, I found 2,595 potentially Claude-related papers. And yet, of these, only a single one investigates Claude 3 Opus’s translation capabilities.

That’s not exactly surprising, considering that Claude 3 Opus was released just 5 months ago, in March. And the latest model, Sonnet 3.5, was released less than a month ago, on the 21st of June. As time progresses, there will undoubtedly be more research papers on the topic.
But for now, let’s delve into the paper at hand—”From LLM to NMT: Advancing Low-Resource Machine Translation with Claude” by the researchers Maxim Enis and Mark Hopkins.
How did they test Claude 3 Opus's translation capabilities?
The researchers evaluated Claude’s translation skills across 37 languages. They used three datasets and two robust evaluation methods. They also compared Claude’s results with those of two “traditional” MT engines: Google Translate and NLLB-54B.
| High-Resource Languages | Low-Resource Languages | Very-Low-Resource Languages |
|---|---|---|
| 1. English | 1. Amharic | 1. Azerbaijani |
| 2. Arabic | 2. Oromo | 2. Nepali |
| 3. French | 3. Gujarati | 3. Pashto |
| 4. Spanish | 4. Hausa | 4. Somali |
| 5. Japanese | 5. Igbo | |
| 6. Hindi | 6. Kinyarwanda | |
| 7. Indonesian | 7. Kyrgyz | |
| 8. Korean | 8. Marathi | |
| 9. Persian | 9. Burmese | |
| 10. Portuguese | 10. Sinhala | |
| 11. Russian | 11. Swahili | |
| 12. Turkish | 12. Tamil | |
| 13. Ukrainian | 13. Telegu | |
| 14. Uzbek | 14. Thai | |
| 15. Vietnamese | 15. Tigrinya | |
| 16. Bengali | 16. Urdu | |
| 17. Yoruba |
The datasets and metrics
This is arguably my favorite part of the study. The researchers leverage three datasets, of which two are completely new ensuring a comprehensive evaluation. Here are the datasets used:
- FLORES-200: This high-quality, robust, human-curated translation dataset from English to 204 different languages. It has largely become an industry standard.
- Maltese speech: A new dataset created from transcriptions and translations for the IWSLT 2024.
- BBC News: Created by the paper’s authors, this dataset consists of BBC News excerpts in 36 languages published after the release date of Claude 3 Opus.
The BBC News dataset is a particularly great addition to their testing. It ensures Claude wouldn’t have seen these strings in its training data, addressing a recurring criticism of LLMs (“learning” vs. memorization).
As for the evaluation metrics, the researchers used widely accepted standards:
- The Bilingual Evaluation Understudy (BLEU): This metric compares a machine translation to one or more reference human translations. It’s based on the overlap of words and phrases between the machine and human translations.
- chrF++: An enhancement of the character n-gram F-score, this metric operates on the character level, making it particularly useful for morphologically rich languages.
These datasets and metrics combined offer a robust framework for assessing Claude’s translation capabilities. In the next section, I’ll dive into the results and what they mean for the future of AI in translation.
Claude 3 Opus's translation performance
Overall, Claude’s translation performance is good. It outperformed Google Translate and NLLB-54B on 25% of language pairs. But this figure is an approximation since Claude’s performance varies significantly depending on the translation direction and the dataset used.
As is common with LLMs, Claude performs substantially better when translating into English rather than from English.
Let’s take a closer look 👇
FLORES-200: Translating into English
When translating the FLORES-200 data into English, Claude significantly outperformed traditional machine translation systems. Here’s a breakdown of its performance:
- Using the chrF++ metric, Claude outperformed in 21 languages.
- When assessed using spBLEU, it outperformed in 20 languages.
In other words, Claude outperformed traditional MT systems 56.9% of the time.

FLORES-200: Translating from English
As you can see in the table below, Claude’s translation performance drops significantly when translating from English into other languages. It only surpasses traditional MTs in the following languages:
- Azerbaijani, Japanese, and Yoruba (using spBLEU).
- Azerbaijani, Burmese, Persian, and Ukrainian (using chrF++).
In other words, it outperforms in 9.65% of instances.

So far, the conclusion seems straightforward. You can start leveraging Claude for your translation projects where the target language is English while avoiding it when translating from English, right?
Well, there’s a catch: Claude’s great performance is unique to the FLORES-200 data.
Why? 👇
BBC: Translating into English
When tested on the BBC dataset, Claude’s performance deteriorates substantially. Regardless of metrics, it only outperforms traditional MTs in 9 languages—that’s a 31.9% drop compared to its performance on FLORES-200 data

BBC: Translating from English
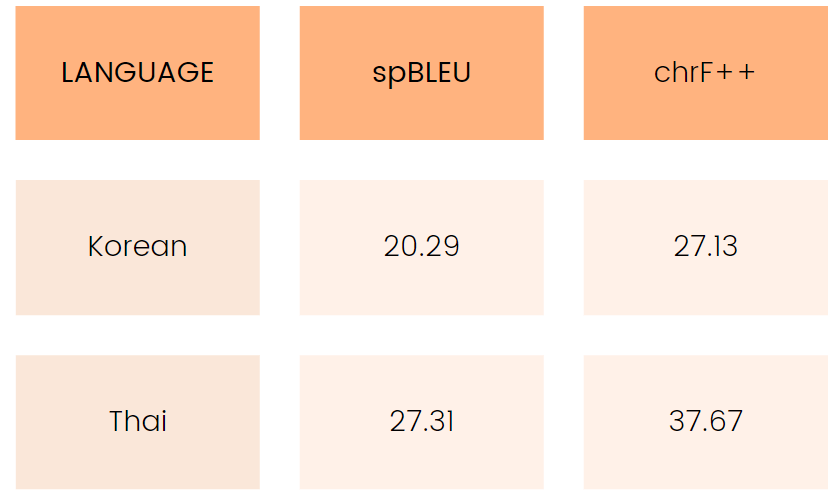
Once again, Claude’s performance decreases when translating from English using the BBC dataset. Regardless of metrics, Claude outperforms Google Translate or the NLLB-54B in only two languages: Korean and Thai.
That’s 2 out of 36 languages! Or 5.56%, which is a 4.09 percentage point drop from its 9.65% performance on the FLORES-200 dataset.
As a side note, the authors also investigated the resource efficiency of Claude relative to 8 other LLMs (including GPT-4 and LLAMA) based on this research. They showed that Claude is more efficient than other LLMs, making it an excellent choice for projects dealing with low-resource languages.
Why does Claude’s performance drop so egregiously?
Claude’s performance drops due to (likely) contamination. In simpler terms, Claude was probably trained on the FLORES-200 data.
While there is no definitive way of knowing, both Google Translate and the NLLB-54B maintain their performance more or less consistently across all datasets (FLORES-200, BBC, and Maltese speech data). But Claude’s performance varies substantially between new and pre-existing datasets, which is an indicator Claude may have been trained on this data.
Of course, unless Anthropic releases Claude’s training data, we won’t know for sure.
Key takeaways
- Claude 3 Opus demonstrates state-of-the-art translation performance. Even when it doesn’t outperform Google Translate or NLLB-54, it comes remarkably close.
- Opus excels in translations into English. If your target language is English, it’s a strong contender.
- For translations from English to other languages, traditional machine translation tools still hold an edge. Stick with them for these tasks.
- Opus shines with very-low or low-resource languages, thanks to its superior resource efficiency. It’s an excellent choice for projects dealing with less common languages.
- While Sonnet 3.5 has yet to be formally tested, it outranks Claude 3 Opus in the LSYMS leaderboard. It may be worth testing internally for your own needs.
- That being said, since the current translation performance of LLMs may be due to contamination, future research should focus on creating novel tests to assess their translation capabilities.
I’d like to leave you with the authors’ thought-provoking closing remark: “Our results point toward a future era of LLM-powered machine translation.”
While LLMs undoubtedly have limitations, the current stream of investments in ever-increasing model sizes almost guarantees performance improvements in the next generation of models (GPT-5, Claude 4, Gemini 2).
The question isn’t if, but how much improvement will we see? Whether we see an incremental uptick or a quantum leap in capabilities is hard to predict, but one thing’s certain: 2024 levels are unlikely to be the ceiling.
If LLMs are indeed shaping the future of machine translation, it behooves us to take the lead. We must embrace this technology proactively, all while maintaining a critical eye. We need to rigorously assess and test these models in real-world scenarios.
Remember, staying ahead in our field isn’t just about adopting new tools—it’s about understanding them deeply. Are you ready to dive into the LLM-powered future of translation?
FAQ
-
They collected English BBC articles.
-
They made the (good) assumption that an article and its translation will use the same images. So, they used Google Reverse Image Search to find potential translations in other languages.
-
They split these articles into sentences
-
They used Facebook’s LASER tool to align matching sentences across languages.
-
They filtered the data, removing low-quality matches.